We introduce a versatile flexible-captioning vision-language model (VLM) capable of generating region-specific descriptions of varying lengths. The model, FlexCap, is trained to produce length-conditioned captions for input bounding boxes, and this allows control over the information density of its output, with descriptions ranging from concise object labels to detailed captions. To achieve this we create large-scale training datasets of image region descriptions of varying length, starting from captioned images.
This flexible-captioning capability has several valuable applications. First, FlexCap demonstrates superior performance in dense captioning tasks on the Visual Genome dataset. Second, a visual question answering (VQA) system can be built by employing FlexCap to generate localized descriptions as inputs to a large language model. The resulting system achieves state-of-the-art zero-shot performance on a number of VQA datasets. We also demonstrate a localize-then-describe approach with FlexCap can be better at open-ended object detection than a describe-then-localize approach with other VLMs. We highlight a novel characteristic of FlexCap, which is its ability to extract diverse visual information through prefix conditioning. Finally, we qualitatively demonstrate FlexCap's broad applicability in tasks such as image labeling, object attribute recognition, and visual dialog.
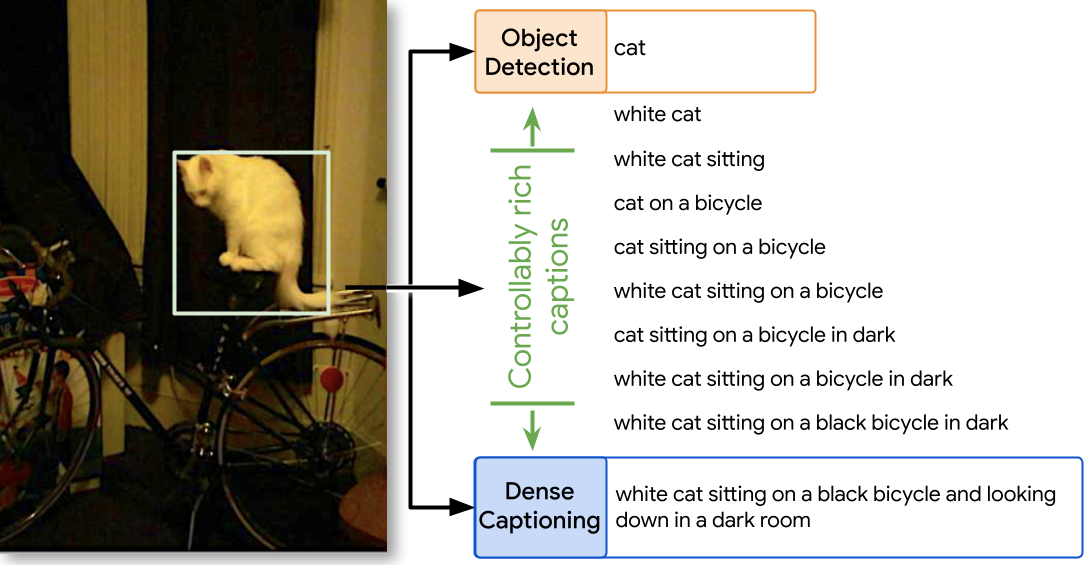
FlexCap generates controllably rich localized descriptions for any region in an image. It has the flexibility to produce captions in a controllable manner which allows the full spectrum of valid descriptions to be explored from short object category names to fully-detailed captions.
For results on Length Conditioned Captions , click on any image below to inspect closely.















FlexCap can help in open-world detection by describing salient regions. Unlike prior dense captioning works, FlexCap generates more diverse sentences to describe visual content in controllable detail.
Here we present interactive showcase of results for region captioning here. Explore the images for Interactive Region-Captioning. Click on any image below to inspect closely.








































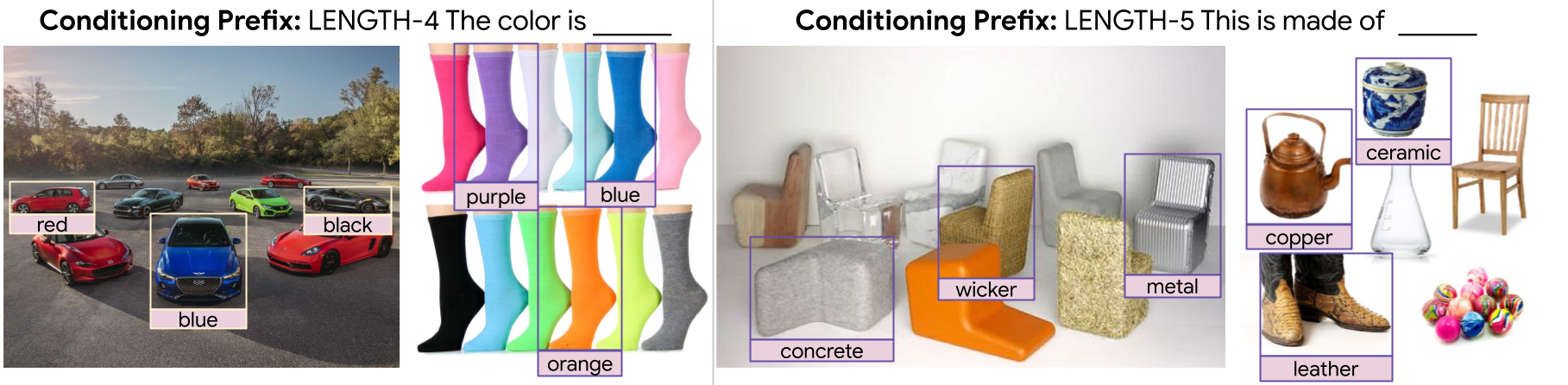
Training FlexCap on a large dataset leads to an emergent capability: the model can extract desired information for a specific image region using input prefixes. We present below some examples of attributes that FlexCap can generate.
Click on the image to inspect the bounding box and caption closely.































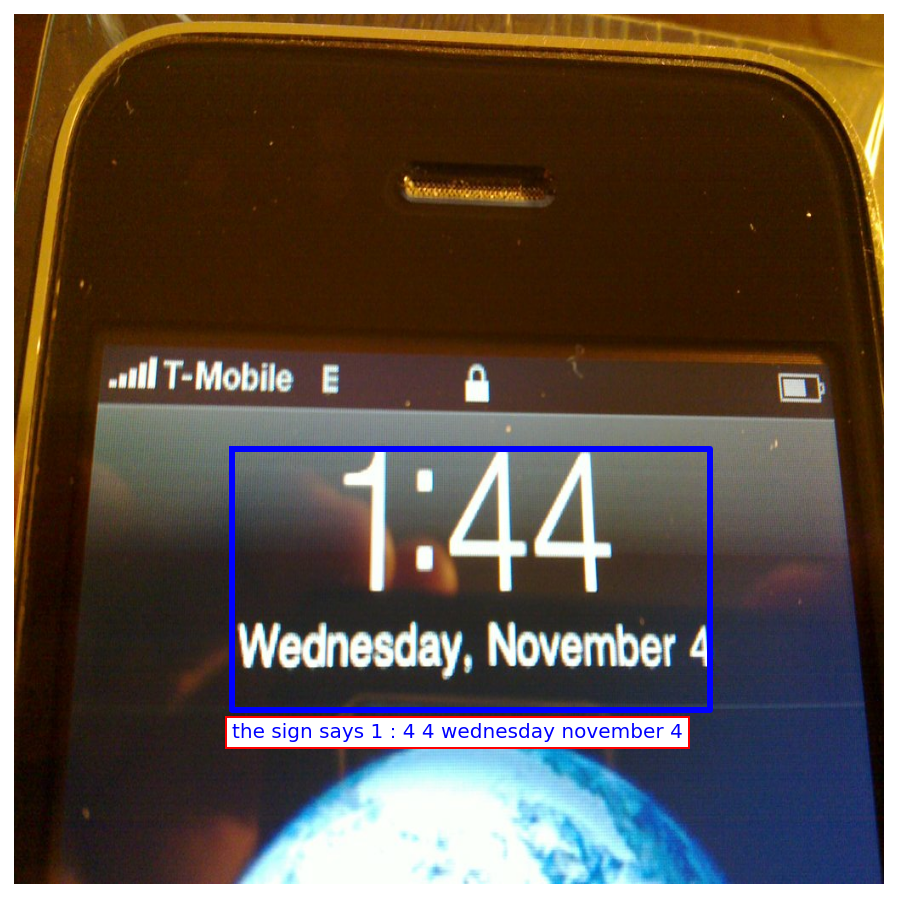

































































































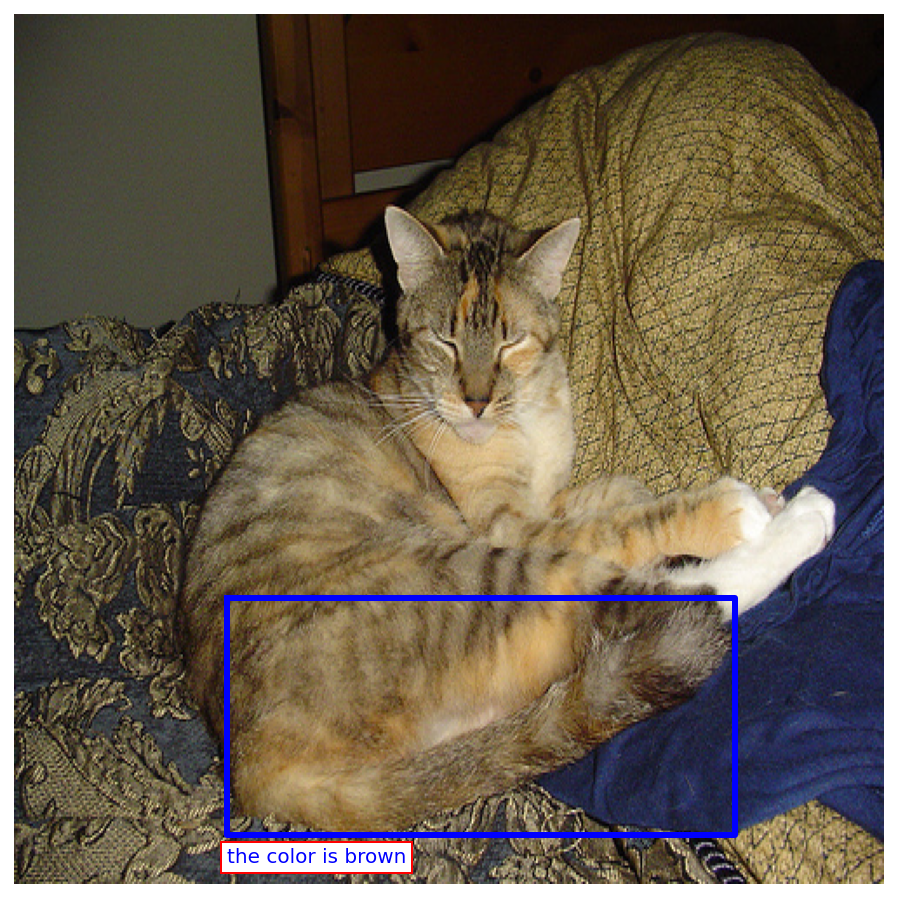





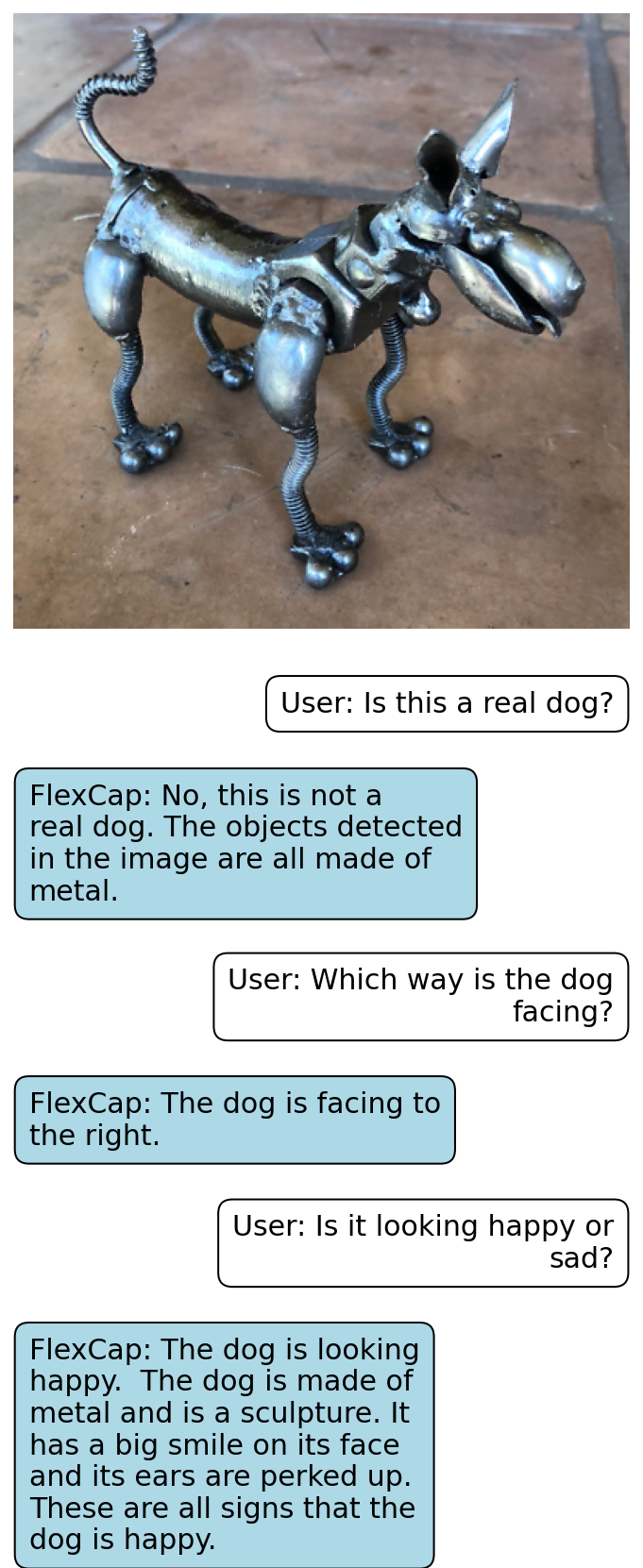
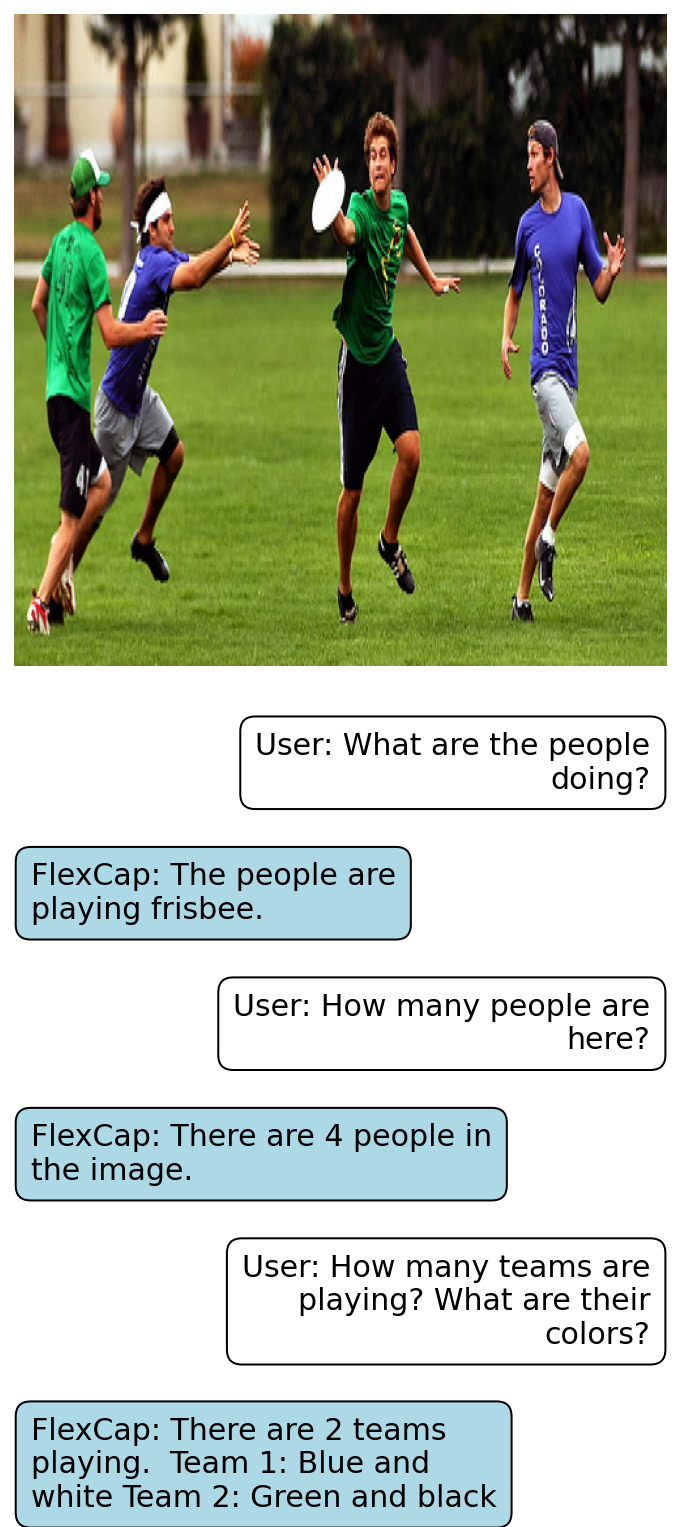
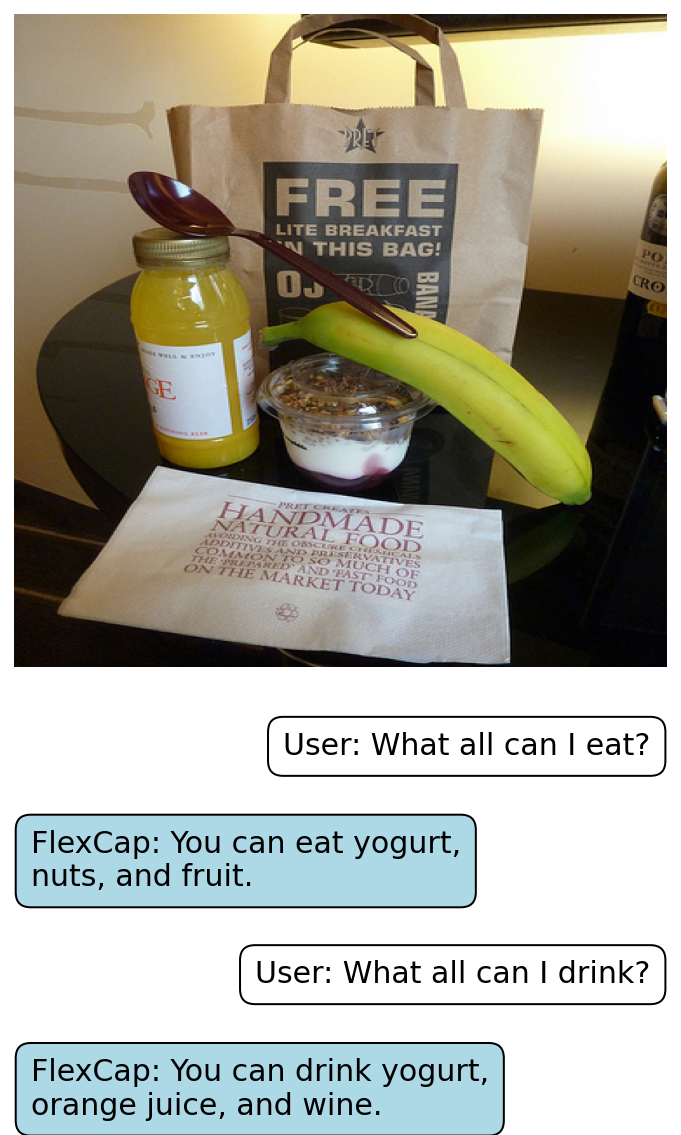
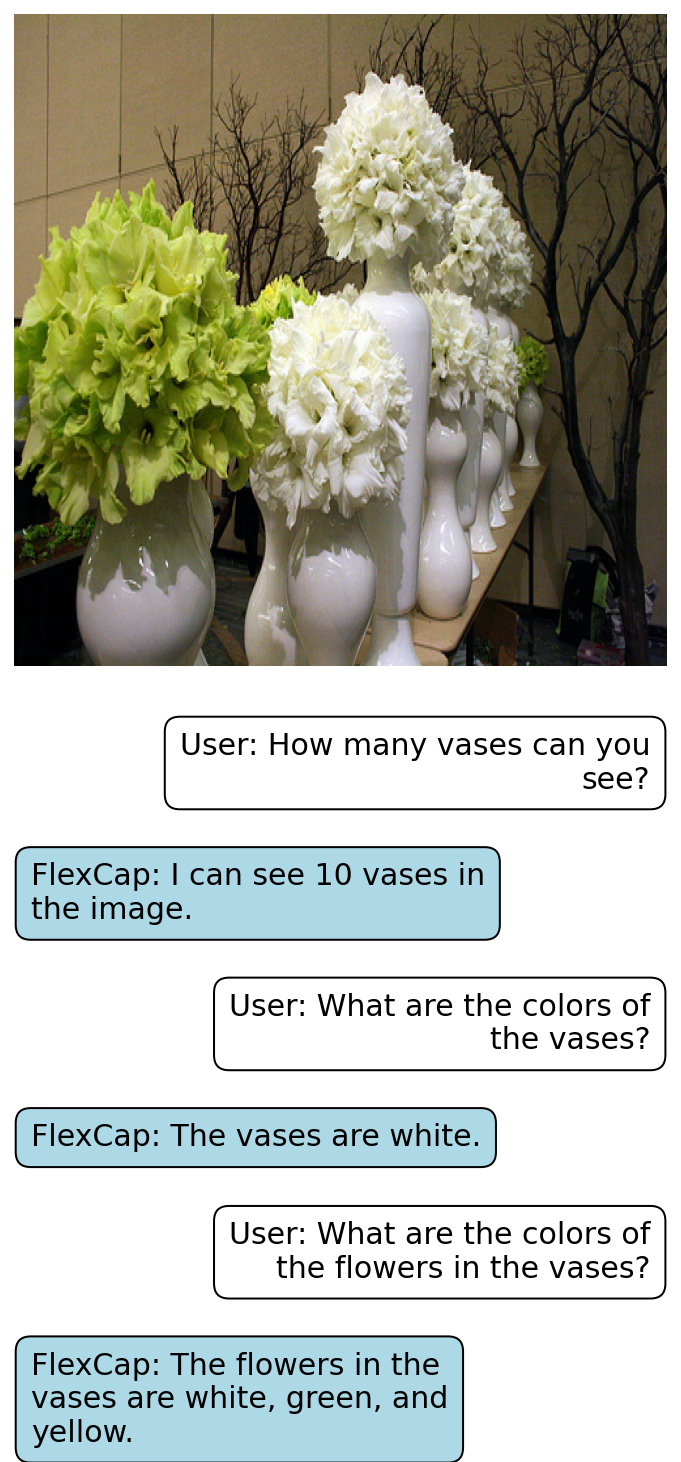
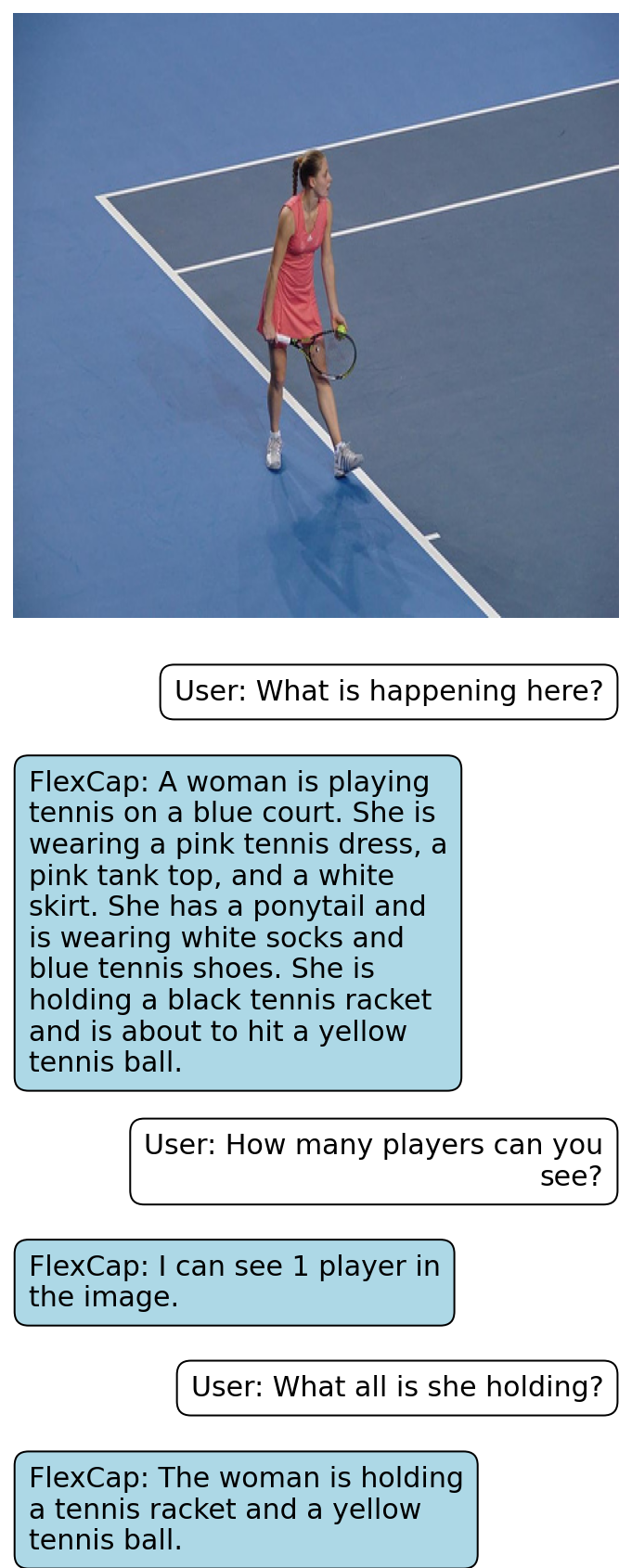
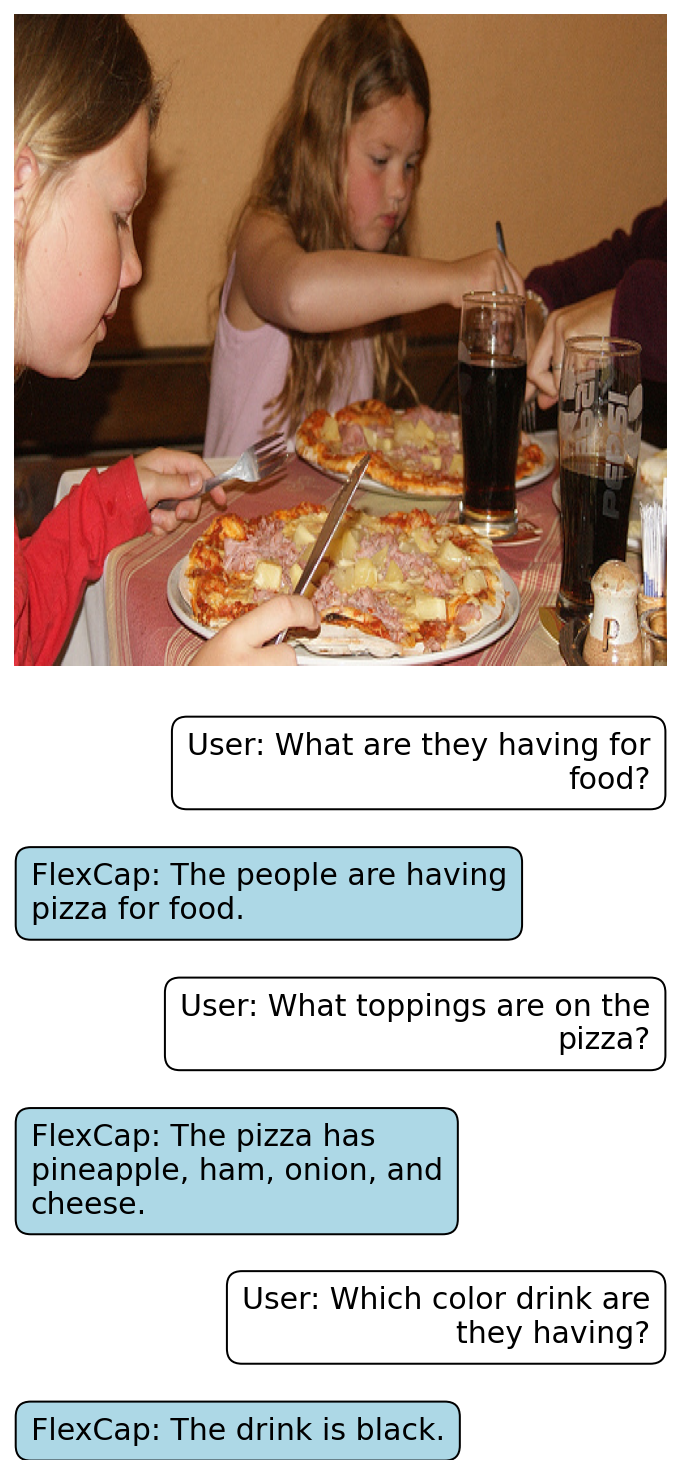
Rich localized captions generated by FlexCap can be easily passed onto Large Language Models (LLMs) to enable zero-shot visual question answering.
Here we present some of the results of FlexCapLLM. Click on any of the images to inspect closely. Note: in the images below "FlexCap" refers to the system "FlexCapLLM".









@inproceedings{
dwibedi2024flexcap,
title={FlexCap: Describe Anything in Images in Controllable Detail},
author={Debidatta Dwibedi and Vidhi Jain and Jonathan Tompson and Andrew Zisserman and Yusuf Aytar},
booktitle={The Thirty-eighth Annual Conference on Neural Information Processing Systems},
year={2024},
url={https://openreview.net/forum?id=P5dEZeECGu}
}